Will Supercomputers and AI Drive Biotech Breakthroughs?
Artificial intelligence and machine learning help researchers to shape large datasets, but incredible computing power is still needed to muscle through biological data in a reasonable time. That's where machines such as Anton 2 and BioHive-1 come into play.
By
Maxx Chatsko
Updated
January 20, 2024
Published
October 20, 2023
Bottom-Up Insights
Software might eat the world, but biotech is proving to be an increasingly big lunch.
Although advances in automation and screening tools such as CRISPR have mitigated experimental throughput bottlenecks and improved standardization, the complexity of biology still creates unique challenges. A lack of precise measurement tools often hinders data collection and the ability to accurately annotate datasets. When it doesn't, labs quickly realize they own a data firehose with two settings: "on" and "off."
The limitations of wetware aren't the only source of complexity. Biotech research increasingly makes decisions from a combination of measured experimental data and predictive computational models. There can be trillions of possible ways to engineer an antibody therapeutic or tweak a metabolic pathway for an industrial organism. The inability to physically build each design requires help from computational models, but the inability to computationally predict biology requires researchers to build as many informed designs as possible.
Advances in the bioeconomy will continue to hinge on an expensive brute-force approach until researchers find a better way. Could artificial intelligence and supercomputers help?
Scientists are cautiously optimistic, so long as modeling improves and computing power scales to match the complexity of biology. Efforts underway at the Pittsburgh Supercomputing Center, Lawrence Berkeley National Lab, Recursion Pharmaceuticals, and Ginkgo Bioworks might provide a glimpse of the future.
Need more finch? Here's our newsletter.
Welcome to The Voyage!
Oops! Something went wrong while submitting the form.
What Is a Supercomputer?
Computers are so seamlessly integrated into modern life it can be easy to forget what they do and how they work. At a basic level, these wondrous machines in your pocket, at your desk, and displaying your video games automate math on a massive scale.
A typical desktop computer can conduct 100 billion to 1 trillion mathematical calculations per second. Each individual calculation doesn't mean much, but when completed in a sequence the answers to many calculations form the basis of computer programs. Math really is the key to the universe, kids.
Computing power is often referred to by the technical name for these mathematical calculations, called floating-point operations per second (FLOPS). A typical desktop computer might have 100 billion FLOPS (100 gigaflops). A PlayStation 5 is more powerful with about 10 trillion FLOPS (10 teraflops), while an Xbox Series X (12 teraflops) is about as powerful as the most advanced supercomputer in the world in 1998.
Those numbers are adorable compared to a modern supercomputer.
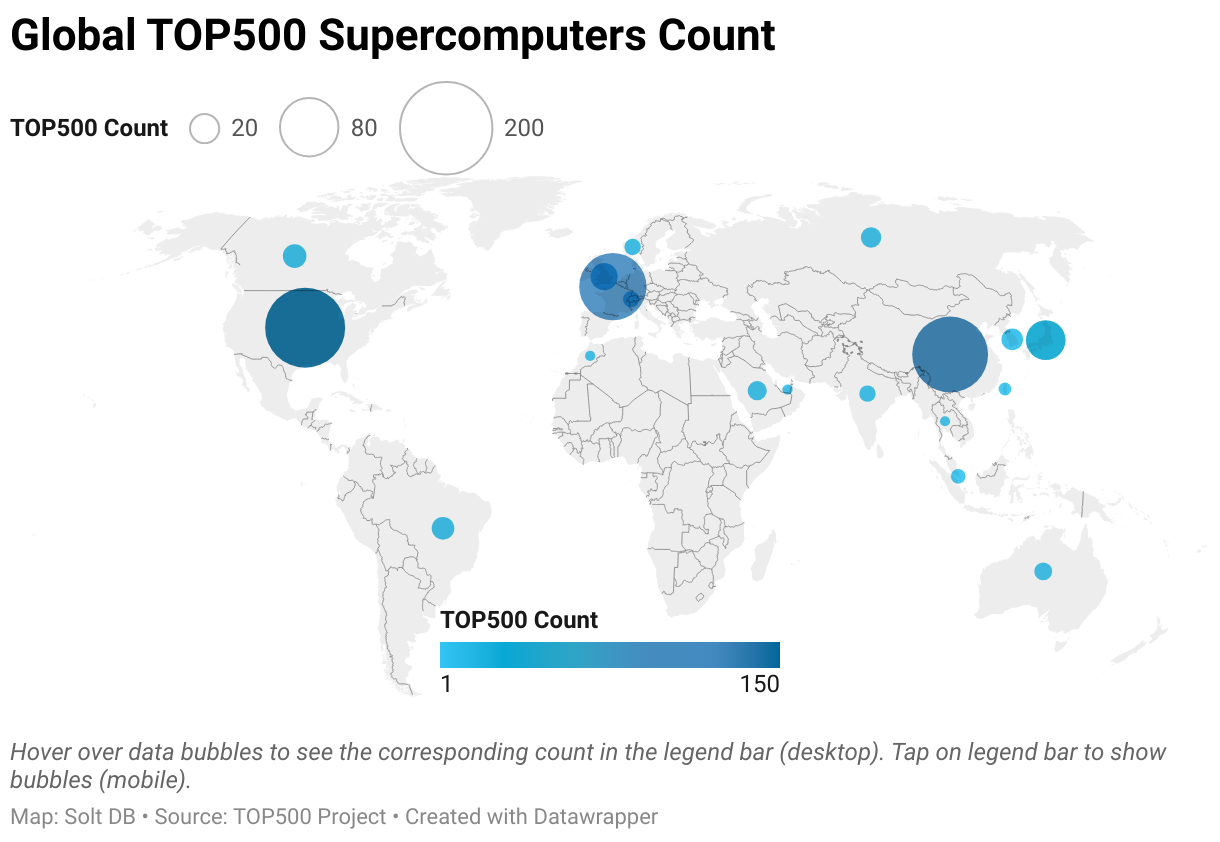
The TOP500 Project publishes annual rankings of the world's most advanced supercomputers. The 500th fastest supercomputer in the world has achieved 1,872 trillion FLOPS (1.87 petaflops), according to the 2023 rankings. The fastest, a machine called Frontier at Oak Ridge National Laboratory, has achieved over 1,194,000 trillion FLOPS (1.19 exaflops). That equals the combined computing power of the top 500 supercomputers on the planet in 2017 and more than any single country's or region's current top 500 output.
As for geopolitical implications, the United States dominates in computational power, wielding 150 of the world's most powerful supercomputers. Only the United States, China (134), and the European Union (104) have more than 100 machines apiece in the top 500.
The computing power of the world's most powerful machines has increased exponentially in recent decades. That's sure to continue, but might take a brief pause in the near future. Two planned systems, El Capitan at Lawrence Livermore National Laboratory and Aurora at Argonne National Laboratory, are each expected to have peak performance of "only" about 2,000,000 trillion FLOPS (2 exaflops). They'll roughly triple the total supercomputing capacity of the United States and increase total global power by about 76%.
Even without El Capitan and Aurora, the United States already dwarfs global peers in total computational power of its top assets. And although Japan has only 33 of the world's top machines, the nation's Fugaku supercomputer is the second-most powerful in the world by a healthy margin.
Massive computing power is arriving at a fortuitous time for biotech research. Advances in screening, discovery, and parallelization of experiments have handed well-equipped labs treasure troves of data. But making sense of it all isn't trivial, even with access to high-performance computing. Not all supercomputers are currently utilized for biology-based research, and biology often requires purpose-built machines and algorithms.
"Everything Scales Perfectly, Until It Doesn't"
AlphaFold 2, the highly publicized breakthrough from Google DeepMind, can predict relatively accurate 3D structures of proteins from a genetic sequence. The artificial intelligence (AI) algorithm was trained on an unusually large, unusually well-annotated dataset. That allowed it to detect patterns -- the core of any machine learning (ML) or AI algorithm -- that weren't always visible to human researchers. It's already been used to predict the structure of 200 million proteins. AlphaFold 2 is valuable, but accurate 3D structures are only so useful. More accurately, they're only the starting point for biotech research applications spanning biopharma and industrial biotech.
A protein's 3D structure changes in response to its environment. It naturally wiggles and moves over time, similar to a tree with many branches swaying in the wind. A protein changes shape when near or attached to another molecule, such as a small molecule or antibody drug candidate. That makes it important to understand not just accurate protein structure (static 3D images), but accurate protein motion (dynamic 4D images, with the fourth dimension being time).
Protein motion is a perfect problem for artificial intelligence and supercomputers.
As the Pittsburgh Supercomputing Center (PSC) demonstrates, a machine doesn't have to appear in the top 500 to make an impact for the bioeconomy. The center's special-purpose supercomputer, Anton 2, made available without cost by by Shaw Research to support non-commercial research, is purpose-built for conducting long-timescale simulations of complex molecular systems. It's the world's fastest system available to the open science community for simulating protein motion.
Specifically, Anton 2 simulates how complex molecular systems change over microsecond timescales in 2.5-femtosecond time slices. The machine can provide 4 billion frames for every 10-microsecond simulation. For comparison, there are 324,000 frames in a three-hour movie that totally doesn't follow the artist's intent from the comic book.
"No other machine has access to the chemical timescales of Anton 2," says Dr. Philip Blood, Scientific Director of the PSC. "It's able to access these timescales because the molecular interactions are calculated with specialized hardware pipeline on tightly-connected custom ASICs. You can add as many GPUs as you want to another system, and it still won't match the performance of Anton 2 for this specific application."
Although the Anton 2 system at PSC is dedicated solely to supporting non-commercial research, Relay Therapeutics, a company solely dedicated to motion-based drug design, utilizes a separate Anton 2 architecture to simulate 4D protein structure. The company's lead drug candidate, RLY-4008 (lirafugratinib), was designed to selectively inhibit FGFR2 proteins in solid tumor cancers while sparing similar-looking proteins in the FGFR family. Simulations on Anton 2 predicted subtle but important differences between a flap on FGFR2 and FGFR1, allowing researchers to design a chemical compound that attached into a binding pocket on the target, but not related proteins.
Using Anton 2, a flap (top left, yellow) on FGFR2 was predicted to open at a different rate compared to FGFR1 and FGFR4, allowing highly-selective drug candidates to be designed. Image Source: Relay Therapeutics.
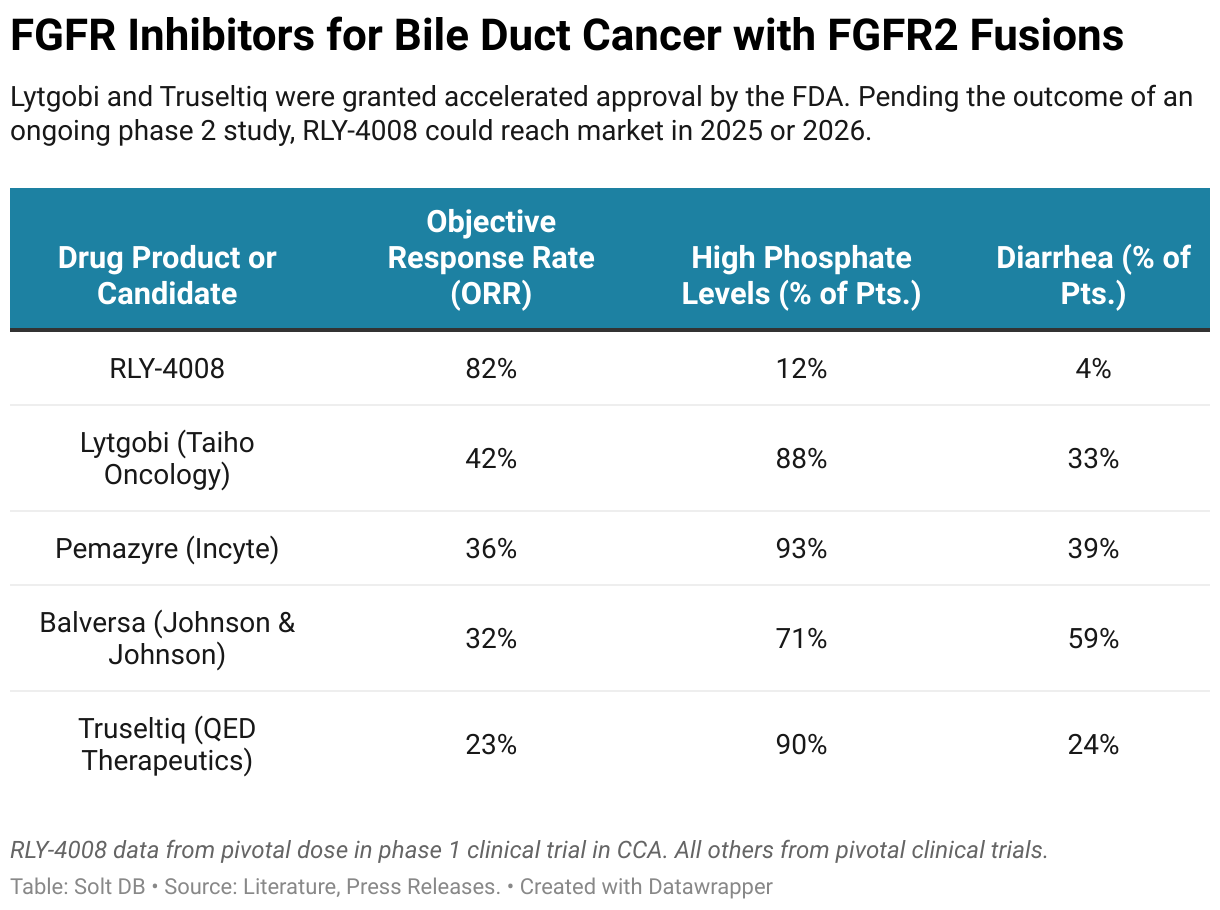
Although several drugs are approved in the United States for FGFR-altered cancers, they also inhibit FGFR1 (causing elevated blood levels of phosphate) and FGFR4 (causing diarrhea). They're selective for FGFR proteins, but not the FGFR2 protein.
Patients taking these drug products experience hyperphosphatemia at least 71% of the time and diarrhea at least 24% of the time, suggesting high rates of off-target (non-FGFR2) inhibition. Dose-limiting toxicities reduce the time a patient can continuously receive treatment or force treatment to be discontinued altogether. Individuals receiving the pivotal dose of RLY-4008 in a phase 1 study experienced hyperphosphatemia and diarrhea 12% and 4% of the time, respectively. Only 1% had to discontinue treatment due to tolerability issues.
Improved tolerability can also lead to improved efficacy. The best-performing drug approved for FGFR-altered cancers demonstrated an objective response rate (ORR) of 42% in its pivotal study. An objective response measures how many individuals saw their primary tumors shrink in size by at least 30%. RLY-4008 notched an ORR of 82% in its phase 1 study for the same tumor type.
Although the response rate could decline in a larger study, the pipeline at Relay Therapeutics has shown a tendency to deliver improved response rates as clinical trials mature, the opposite trend of the industry. That suggests the company's key hypothesis -- highly selective drug candidates have fewer side effects, which means they can be dosed longer, which means they could drive deeper responses over time -- could be proven correct over time.
Based on promising initial results, the U.S. Food and Drug Administration (FDA) will allow the ongoing phase 2 clinical trial for RLY-4008 to serve as the pivotal trial in the most common FGFR2-altered cancer. Forgoing a phase 3 clinical trial can reduce total development costs by at least $150 million and shorten development timelines by at least 18 months. RLY-4008 is expected to become the first supercomputer-designed drug candidate to earn FDA approval by 2026.
Although Anton 3 is on the way (it'll be at least 10x faster than its predecessor), Anton 2 highlights the value of a purpose-built machine. Computers are key to the function of an Apple Watch, a PlayStation 5, and a brand new 2024 Honda Civic, but hardware and software must be closely matched to a device's function. Purpose-built machines excel at specific functions and sequences of calculations, but flexible and highly-available general-purpose systems still support the vast majority of scientific computing. Anton 2 was specifically built to simulate molecular motion faster than anything else, but that's the only type of calculation it performs.
"The history of scientific computing can be summarized as, 'Everything scales perfectly, until it doesn't,'" quipped Alex Ropelewski, Director of the Biomedical Applications Group at the PSC. His work focuses on the National Institutes of Health (NIH) BRAIN Initiative, which uses microscopy images and spatial transcriptomics of animal and human brains. It uses the center's Bridges-2 supercomputer. The petabyte-sized datasets (1 petabyte = 1 million gigabytes) of the BRAIN Initiative require thoughtful consideration for the type of hardware used for computing, the algorithms used in the model, as well as easy-to-overlook software configurations handling data storage, retrieval, and access.
Those considerations aren't always built into how data are generated or prepared in biology-based fields.
"We Have the Knowledge, But…"
Automated biology labs allow Recursion Pharmaceuticals to design, build, and test more chemical and biological designs during drug discovery. Merging multiple disciplines requires a shift in mindset and company culture. Image Source: Recursion Pharmaceuticals.
Dr. Kristofer Bouchard, Principal Investigator in the Neural Systems and Data Science Lab at Lawrence Berkeley National Lab (LBNL) and leader of the Computational Biosciences Group, admits his neuroscience background trained him to think differently when working at the intersection of biology, data, and modeling. "Systems neuroscience isn't as limited by data, as, for example, synthetic biology, so researchers have built interpretable and predictive models. In such cases, a first-principles approach could help define initial models, that are then refined with experimental data."
That highlights one of the biggest challenges in applying advanced computational models to biotech research: A lack of large, well-annotated datasets needed to train advanced algorithms in the first place. If a model is constructed on a small sample size, then the patterns detected might not be representative of the complexities of the real world. That might make a model useful only in narrow applications, if at all.
For example, even though AlphaFold 2 was trained on a relatively large and well labeled dataset for biology, it doesn't provide accurate structures for every protein or every folded structure. In the competition where it made its breakthrough debut, its computational predictions were less accurate than experimental predictions one third of the time. AlphaFold 2 is powerful, but understanding its nuanced performance helps to put biology's data challenge into perspective.
Some fields of biology are better positioned than others. The field of neuroscience and problems such as de novo DNA assembly (a derivative of DNA sequencing) have sufficient data measured in both size and labeling. This allows researchers to take advantage of advanced computational models and supercomputers. Not all are so lucky.
Dr. Bouchard is also engaging with colleagues at the Advanced Biofuels and Bioproducts Process Development Unit (ABPDU) on specific projects in industrial biotech, such as using genetically engineered microbes to produce chemical ingredients. Unfortunately, surprisingly little data are captured from commercial-scale fermentation. That hinders the ability to utilize advanced computational resources for developing more efficient bioprocesses or designing novel bioreactors, which could help to mitigate the industry's economic challenges.
Whether working on neuroscience or computational biosciences projects, he still utilizes his neuroscience training. "Even when we don't have enough data, I aim to get something. It might not be perfect, but it's better than nothing and serves as the foundation for refinements." In either case, the difference between using local computer clusters or sending data workflows to the National Energy Research Scientific Computer Center (NERSC) can be the difference between one week or 30 minutes of computational time, assuming the queue works in his favor. High-performance computer resources are only valuable if you can access them.
LBNL Research Scientist Tyler Backman suggested ways for industrial biotech to benefit from advances in computational modeling. The discipline of retrobiosynthesis aims to work backward from a target molecule to an enzyme capable of creating it. The primary challenge is that most molecules require multiple synthesis steps, each representing a specific enzyme, and each enzyme has billions or trillions of possible designs.
"Designing metabolic pathways is well-suited for supercomputers. Any problem involving a combinatorial explosion of outcomes, where the complexity scales rapidly based on inputs, that also has sufficient experimental data could benefit from computational power," explained Backman. That suggests other modern challenges in bioprocessing, such as design of experiments, could benefit from advanced computational tools.
Even then, there's a cultural hurdle in biology-based fields. "We have the tools and knowledge to productively use supercomputers to advance microbial processes, but much of the field is using 20th century techniques to generate, store and utilize data," says LBNL staff scientist Hector Garcia Martin. He argues for more cooperation:
"The field could benefit from more collaboration, rather than focusing exclusively on individual projects. Imagine a moonshot project aimed at quantitatively predicting single cell E. coli behavior. The success of that kind of project could potentially enable researchers to create programmable chemical factories by just asking a computer: 'We want a chemical with this chemical property. How can we make it?'"
Garcia Martin's pitch for an E. coli modeling moonshot could lead to one of the most valuable foundation models ever created. Stanford researchers introduced the buzzy and controversial term to make a distinction from large language models (LLMs). Foundation models aren't just focused on written language and don't just reprocess inputs. As OpenAI has demonstrated with GPT-4, foundation models can generate new content across multiple domains.
Several technology-enabled drug developers and synthetic biology foundries have retained the term LLM when referring to their own attempts at creating foundation models. That may still be appropriate, but it points to one big challenge: Biology might be a language, but it wasn't written by humans.
When Will Biology's ChatGPT Moment Arrive?
BioHive-1 is one of the fastest supercomputers in the world, according to the TOP500 Rankings for 2023. Can it help create one of biology's first significant foundation models and deploy it at scale? Image Source: Recursion Pharmaceuticals.
Jason Kelly, co-founder and CEO of Ginkgo Bioworks, knows the challenges and opportunities of working with large biological datasets all too well. The company's automated labs generate significant streams of data across microbial, mammalian, and plant hosts. A lack of accurate computational models can still result in frustrating speed limits at times.
"Biotech hasn't had its ChatGPT moment yet. We had AlphaFold 2, which is amazing, but that's backward-looking. It hasn't deciphered the rules of protein folding for humans. A breakout generative AI in biology would be forward looking, meaning it can receive a series of design prompts and hand scientists new designs or insights."
Ginkgo Bioworks is leveraging its massive datasets to build and test models, then, if they work, integrate them to improve the efficiency of the overall platform. The company recently forged a strategic partnership with Google Cloud to accelerate the process. Scientists will aim to develop LLMs with good predictive capabilities for engineering biology by leveraging the computational power of Google Cloud's Vertex AI platform.
That followed a similar collaboration between Recursion Pharmaceuticals and NVIDIA, which will leverage the NVIDIA DGX Cloud to accelerate the training of foundation models for generative AI in drug discovery. Both Ginkgo Bioworks and Recursion Pharmaceuticals said they'll explore licensing foundation models to other companies and researchers.
In addition to utilizing cloud resources, Recursion Pharmaceuticals owns BioHive-1, the 125th most-powerful system on the global TOP500. The in-house asset allows the company to build maps of biology that inform drug discovery and drug design decisions. Doing so still requires a shift in approach and mindset.
For example, the human genome spans about 20,000 genes. Researchers at the company completed the task of knocking out roughly 17,000 of them, one at a time, and using machine learning to better understand each gene's role in relation to every other gene and compound screened.
Knocking out or silencing a gene might lead to an increase in the activity of another seemingly unrelated gene. This process, called genetic compensation, evolved to retain and restore function when things go wrong at the genetic level. Even without compensation, silencing a gene in a targeted location can impact gene expression in distant parts of the genome. If researchers aren't looking across the full genome, then they'll likely miss these complex interactions.
"Building maps of biology requires taking a multi-gene approach, which requires significant computing," says Dr. Imran Haque, SVP of AI and Digital Services at Recursion Pharmaceuticals. "Biologists traditionally design narrow experiments, then test a narrow hypothesis. This can also be said of traditional drug development. The reason we take a high-dimensional approach is to understand why 'unexpected' things happen, so we can learn faster."
Recursion Pharmaceuticals is developing multiple models to aid specific parts of the drug discovery and drug design process.
In one example, it leveraged BioHive-1, AlphaFold 2, and the Enamine REAL Space chemical library to predict how a database of over 36 billion small molecules would interact with more than 15,000 human proteins containing over 80,000 binding pockets. The model could accelerate drug discovery efforts by allowing scientists to focus on novel chemical compounds with specific drug-like properties for specific types of proteins. Additionally, it could screen chemical space more efficiently before sending jobs to BioHive-1 or to the wet lab for validation, saving computational and experimental time.
The company has also teased progress training foundation models for generative AI in the drug discovery process. The model was trained using a proprietary dataset of over 1 billion annotated images of human cells. To test the model, scientists masked 75% of a known image of multi-cellular human biology, then asked the algorithm to predict the missing pieces. The generated image closely matched the original image, suggesting the model has a fair amount of accuracy.
Recursion Pharmaceuticals is building foundation models based on a proprietary dataset of over 1 billion annotated images of human biology. Image Source: CEO Chris Gibson / Twitter.
If scientists can continue to refine the model above, then it could be one of the first applications of a foundation model being used at scale in the drug discovery process. For example, it could be used to predict what chemical compounds would have a desired impact, such as repairing diseased tissue or shrinking tumors, by looking at images of cells. Haque is excited for the future, but knows researchers will need to remain humble. "Even within biology's most widely accepted ideas, uncertainty is always lurking."
Disclosure: Maxx Chatsko owns shares in Relay Therapeutics and Recursion Pharmaceuticals. Solt DB Invest's coverage ecosystem includes Ginkgo Bioworks, Relay Therapeutics, and Recursion Pharmaceuticals. Solt DB Invest provides research for stocks that are both undervalued and overvalued at any given time.
(free stuff and recent articles below)
Is that biotech stock a buy?
Solt DB is a biotech equities research firm. Support Solt DB for just $225 per year and gain access to our expert research, insights from our proprietary financial models, and real-money investing performance.
Subscriptions to investment research fund our mission as a public benefit company. The finch explores the business of biotech by publishing free content (like this article), maintaining open-source databases, and donating 6% of revenue to decarbonization and Nucleate Pittsburgh.
Jump into the database. The Solt DB Biotech Company Database is tracking every biotech company on the planet, past and present, to develop greater insights into the bioeconomy. It's free and open (and you can add companies).
.svg)
%20(squoosh)%20(resized).jpg)


%20(squoosh)%20(resized).jpg)
%20(squoosh)%20(resized).jpg)

.svg)






-cropped.svg)